
千帧长视频时代到来!MIT全新扩散算法让任意模型突破时长极限
千帧长视频时代到来!MIT全新扩散算法让任意模型突破时长极限进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
来自主题: AI技术研报
9104 点击 2025-02-26 13:39
 搜索
搜索
进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
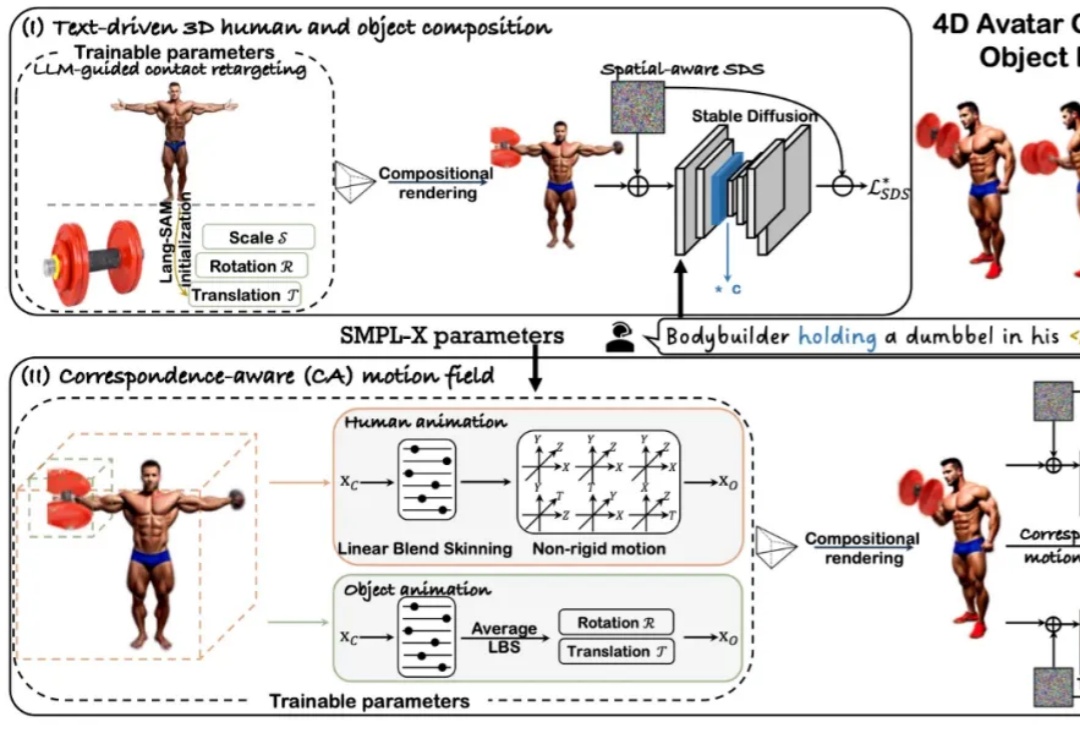
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 - 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。
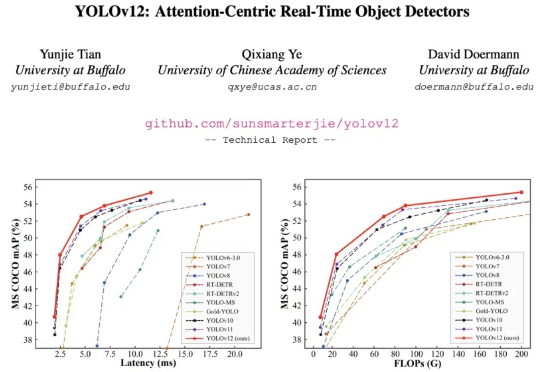
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。

正如论文一作所说,「新架构 Titans 既比 Transformer 和现代线性 RNN 更有效,也比 GPT-4 等超大型模型性能更强。」
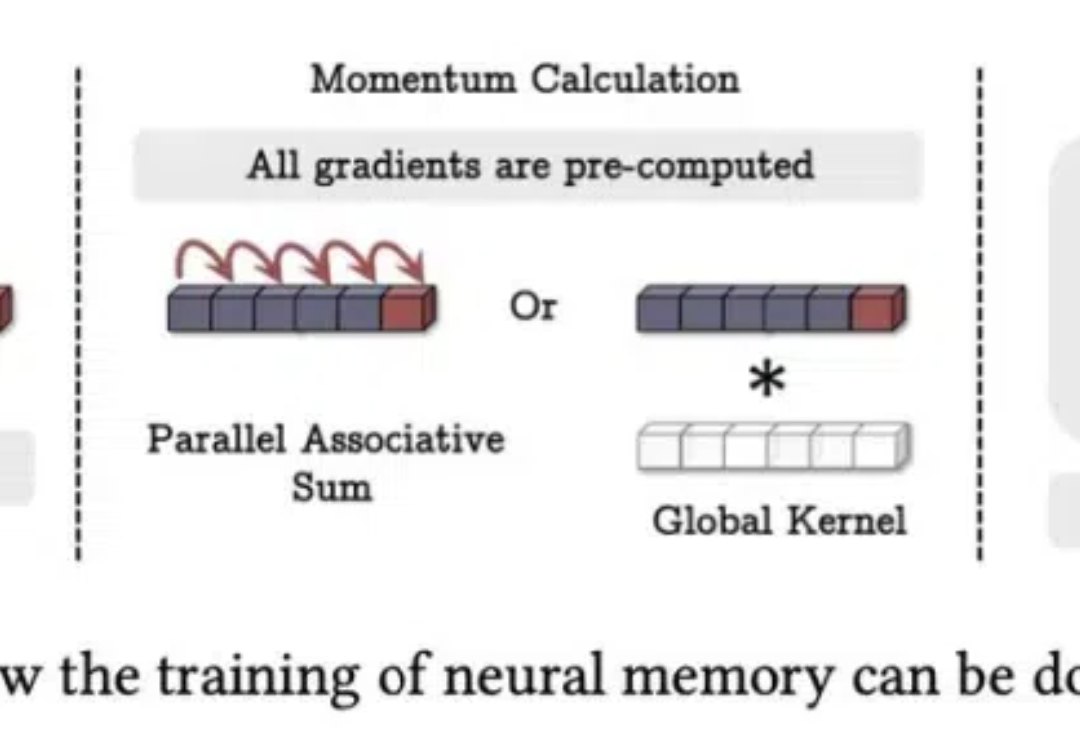
想挑战 Transformer 的新架构有很多,来自谷歌的“正统”继承者 Titan 架构更受关注。

Mamba 这种状态空间模型(SSM)被认为是 Transformer 架构的有力挑战者。近段时间,相关研究成果接连不断。而就在不久前,Mamba 作者 Albert Gu 与 Karan Goel、Chris Ré、Arjun Desai、Brandon Yang 一起共同创立的 Cartesia 获得 2700 万美元种子轮融资。
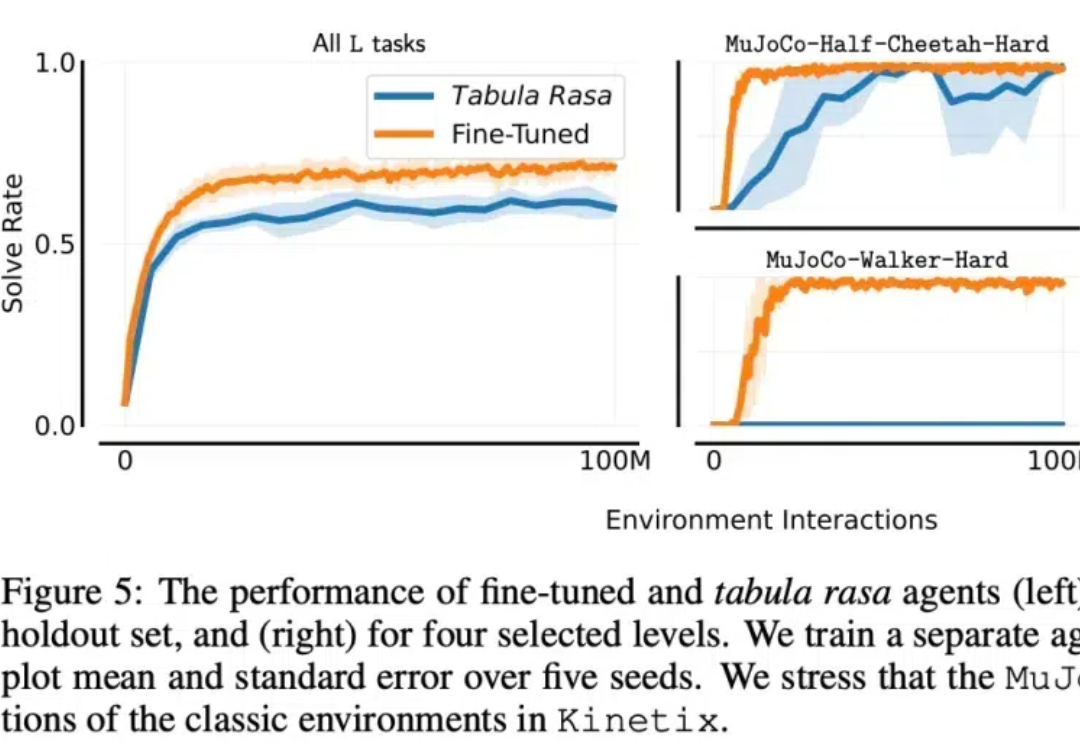
在机器学习领域,开发一个在未见过领域表现出色的通用智能体一直是长期目标之一。一种观点认为,在大量离线文本和视频数据上训练的大型 transformer 最终可以实现这一目标。

Sora 的发布让广大研究者及开发者深刻认识到基于 Transformer 架构扩散模型的巨大潜力。作为这一类的代表性工作,DiT 模型抛弃了传统的 U-Net 扩散架构,转而使用直筒型去噪模型。鉴于直筒型 DiT 在隐空间生成任务上效果出众,后续的一些工作如 PixArt、SD3 等等也都不约而同地使用了直筒型架构。
新一代通用灵活的网络结构 TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters 来啦!

Transformer自问世后就大放异彩,但有个小毛病一直没解决: 总爱把注意力放在不相关的内容上,也就是信噪比低。 现在微软亚研院、清华团队出手,提出全新改进版Differential Transformer,专治这个老毛病,引起热议。